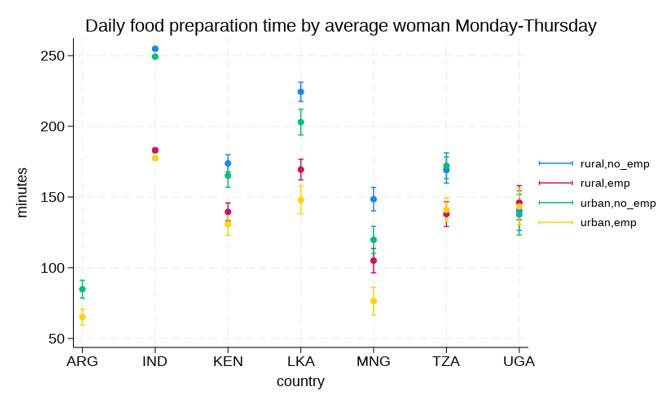
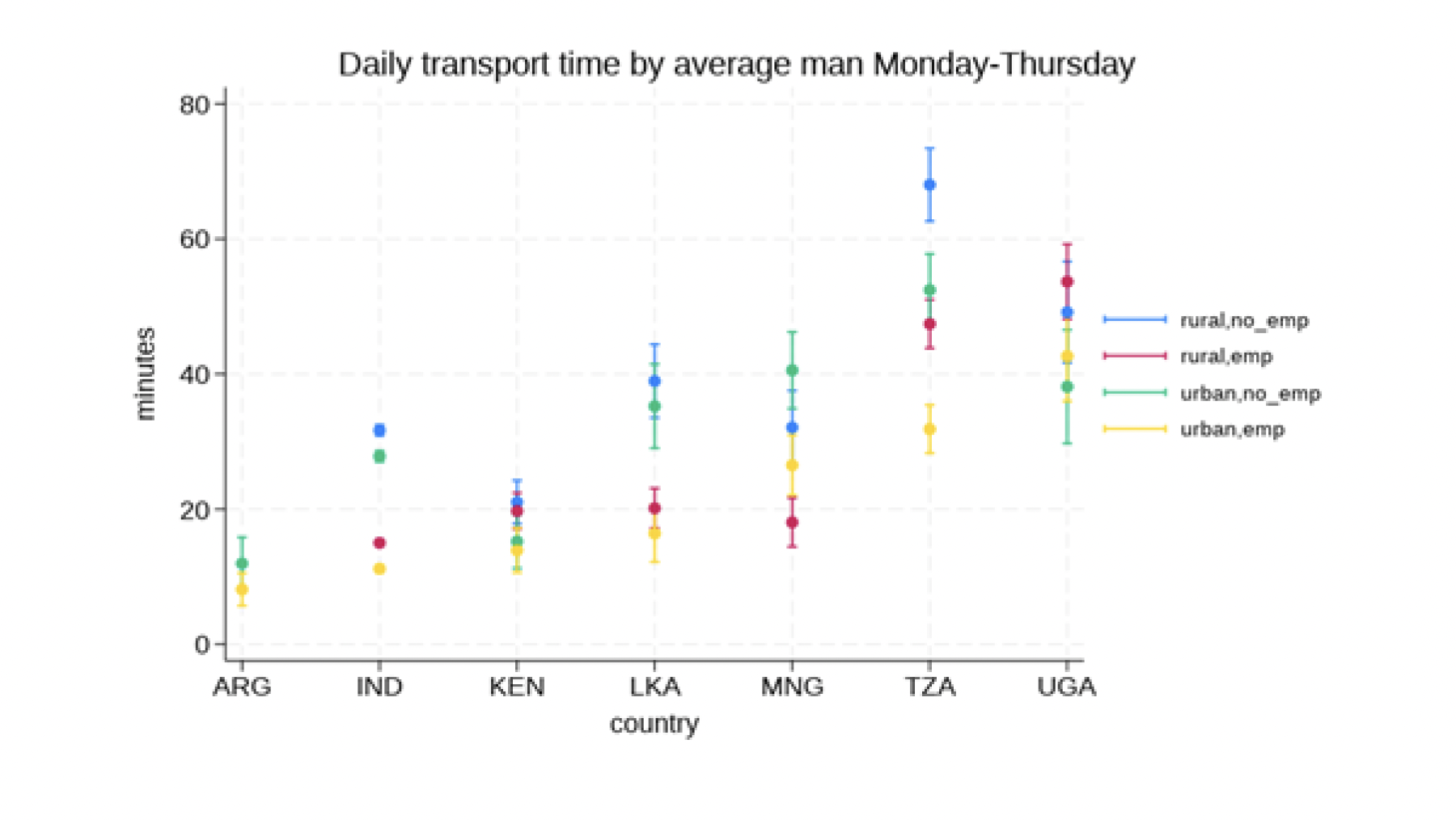
For researcher Lotte Ansgaard Thomsen at Aalborg University, UCloud has played a central role in the research project UpperAtmosphere, where she combines artificial intelligence, satellite data and physical models to better understand conditions in the upper atmosphere.
Many satellites operate in this part of the atmosphere, where conditions can change quickly due to solar activity. However, traditional physical models do not always capture these rapid changes accurately. To address this, Lotte uses AI to learn patterns from different data sources and improve the physical model.

Lotte Ansgaard Thomsen is an Associate Professor in the Department of Sustainability and Planning at Aalborg University. In her current research project, she investigates how AI can be used to improve the understanding of key variables in the upper atmosphere. This can contribute to more accurate models of the space environment where satellites operate and provide better insight into the conditions that may affect satellite performance, communication systems, and space-based infrastructure.
Combining AI and physical models
A key part of the project is the combination of several different data sources. Satellite measurements, solar activity data and ionospheric data each contribute with important information. When these data sources are used together, the AI model can improve the physical model significantly. According to Lotte, this combination is one of the central insights of the project so far:
“A key insight is combining different data sources really matters. Satellite measurements, solar activity, and ionospheric data each add something unique. When I use them together in AI on top of the physical model, the model improves significantly.”
Using UCloud as the primary platform
Lotte has used UCloud as the primary platform for running the computational work in the project. A large part of this involves training AI models, which requires substantial computing power because the datasets are large and the models need many iterations to find the right architecture. However, UCloud has not only been used for the heavy computations at the end of the process. It has also supported the development and testing of code along the way.
“It gives me a good environment to build the workflow, try things out, and adjust as I go.”
Lotte also uses UCloud in another research project, where large language models are used to work with environmental data. Across both projects, access to computing power has been essential.
“In both projects, we simply could not have done the work without access to this kind of computing power or a similar alternative.”
Access to computing power made results possible faster
When Lotte moved from industry into academia, she was concerned about whether she would have access to enough computing power for her research. Discovering that UCloud existed was therefore an important advantage.
“It was really nice to discover that UCloud existed. Having access to that number of resources has been a big advantage for the project.”
With UCloud, Lotte could access the computing power needed without first having to apply for separate funding. This made it possible to move faster from development to results.
“If I did not have access to UCloud or another free service, and first had to apply for funding just to get compute, it would have been impossible to have results so fast.”
A user-friendly platform for research
According to Lotte, one of the main benefits of UCloud is its user-friendly setup for research and development work.
“First of all, UCloud is really well-suited for development work. It gives me a good environment to build and test my workflow, and for research work, I have found that it has a very user-friendly interface.”
She has used Visual Studio Code, a code editor used for writing, testing and developing code, on UCloud, which gives her a setup similar to the one she uses locally. This makes it easier to move between local development and cloud-based work. Another important advantage has been the possibility to scale up and access more compute when needed.
“It has been very easy to scale up and get more compute when I need it.”
Fast support makes a difference
For Lotte, the support around UCloud has also been an important part of the experience. When working with complex research projects, technical issues can slow down the research process. In her experience, the support team has responded quickly when challenges have occurred.
“If I run into any issues, the team helps almost immediately. That makes a big difference when working on complex projects.”
Lotte has received support from Aalborg University’s local front office, which helps researchers get started with UCloud and provides support when questions or technical issues arise. All Danish universities have a local front office where researchers can get support.
Overall, UCloud has provided Lotte with access to the computing resources, development environment and support needed to work with large datasets, AI models and complex research workflows.
“I think UCloud is a really good solution overall. When people talk about the need for more European cloud alternatives, this is the kind of thing I think of.”
This work was supported by DeiC National HPC (g.a. DeiC-KU-L1-291125). Read more about DeiC’s calls for resources on HPC-platforms: Grants og funding | DeiC.